
Visualising your fitted non-linear dimension reduction model in the high-dimensional data space
![]()

quollr
questioning how a high-dimensional object looks in low-dimensions using r
Motivation
Single-cell gene expression: same data, different NLDR + hyper-parameters
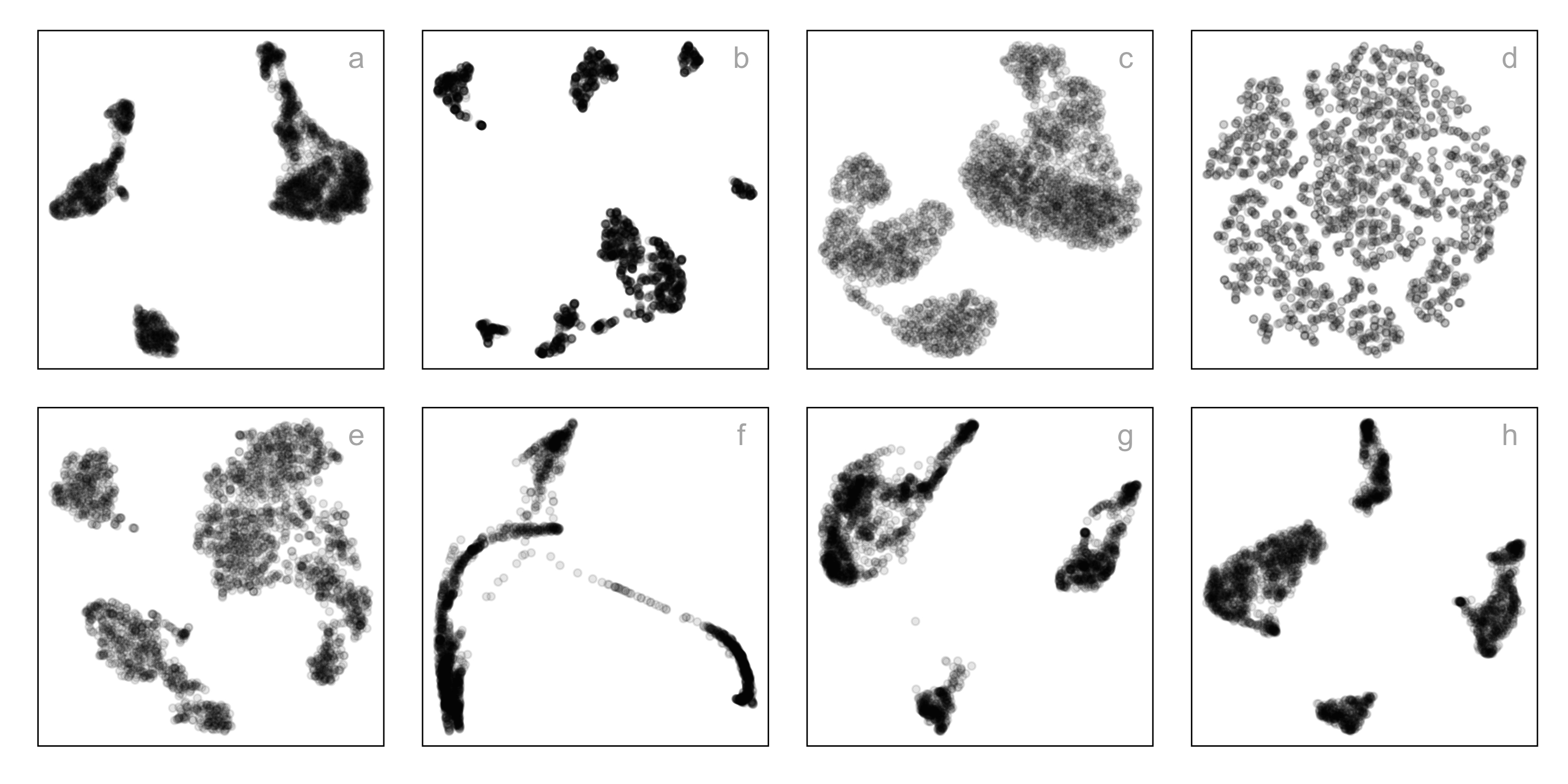
data-in-the-model-space
model-in-the-data-space
data-in-the-model-space
model-in-the-data-space
Overview of method
1. Construct the \(2\text{-}D\) model
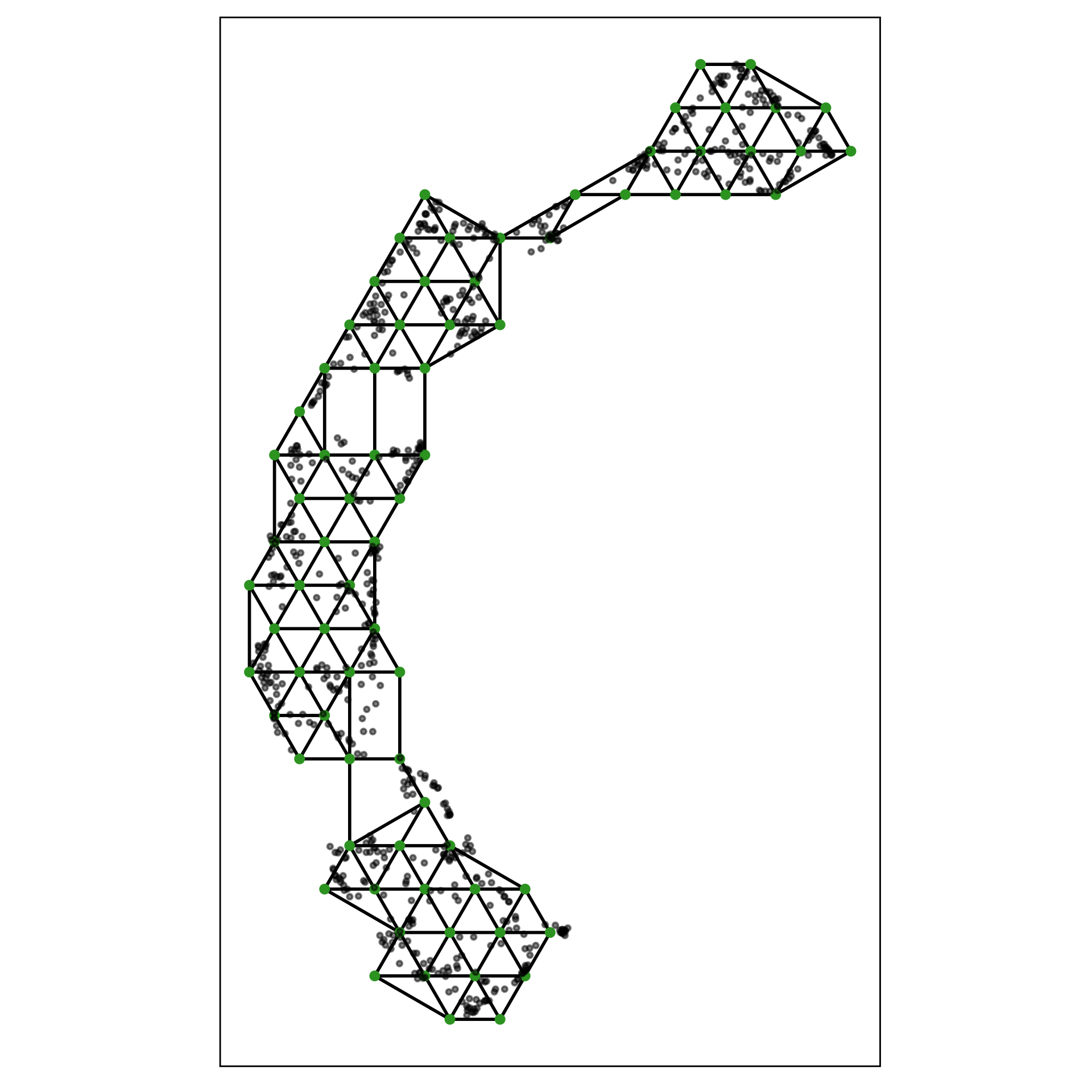
2. Lift the model into high-dimensions
Steps of the algorithm
1. Construct the \(2\text{-}D\) model

- NLDR layout, b. hex bin (
hex_binning()andgeom_hexgrid()), c. bin centers (extract_hexbin_centroids()), d. triangulation wire frame (tri_bin_centroids(),gen_edges()andgeom_trimesh()).
Steps of the algorithm
2. Lift the model into high-dimensions
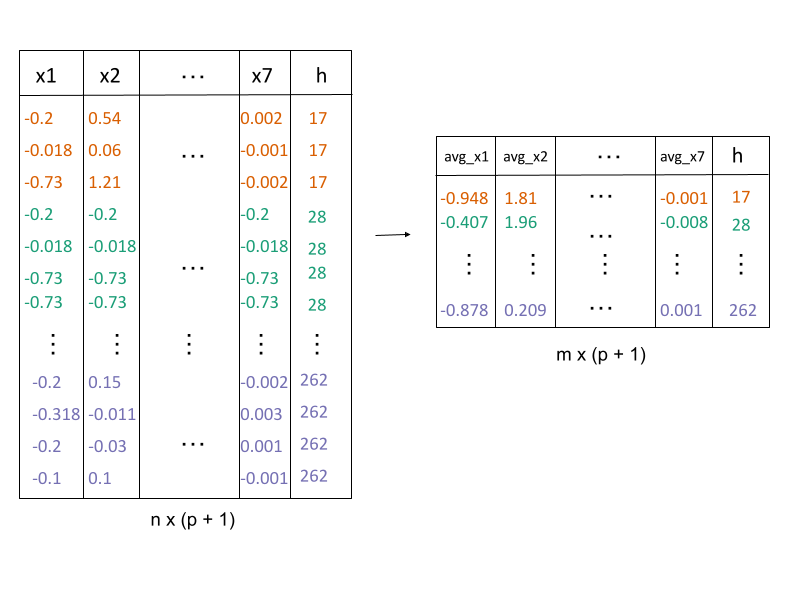
avg_highd_data()
show_langevitour()
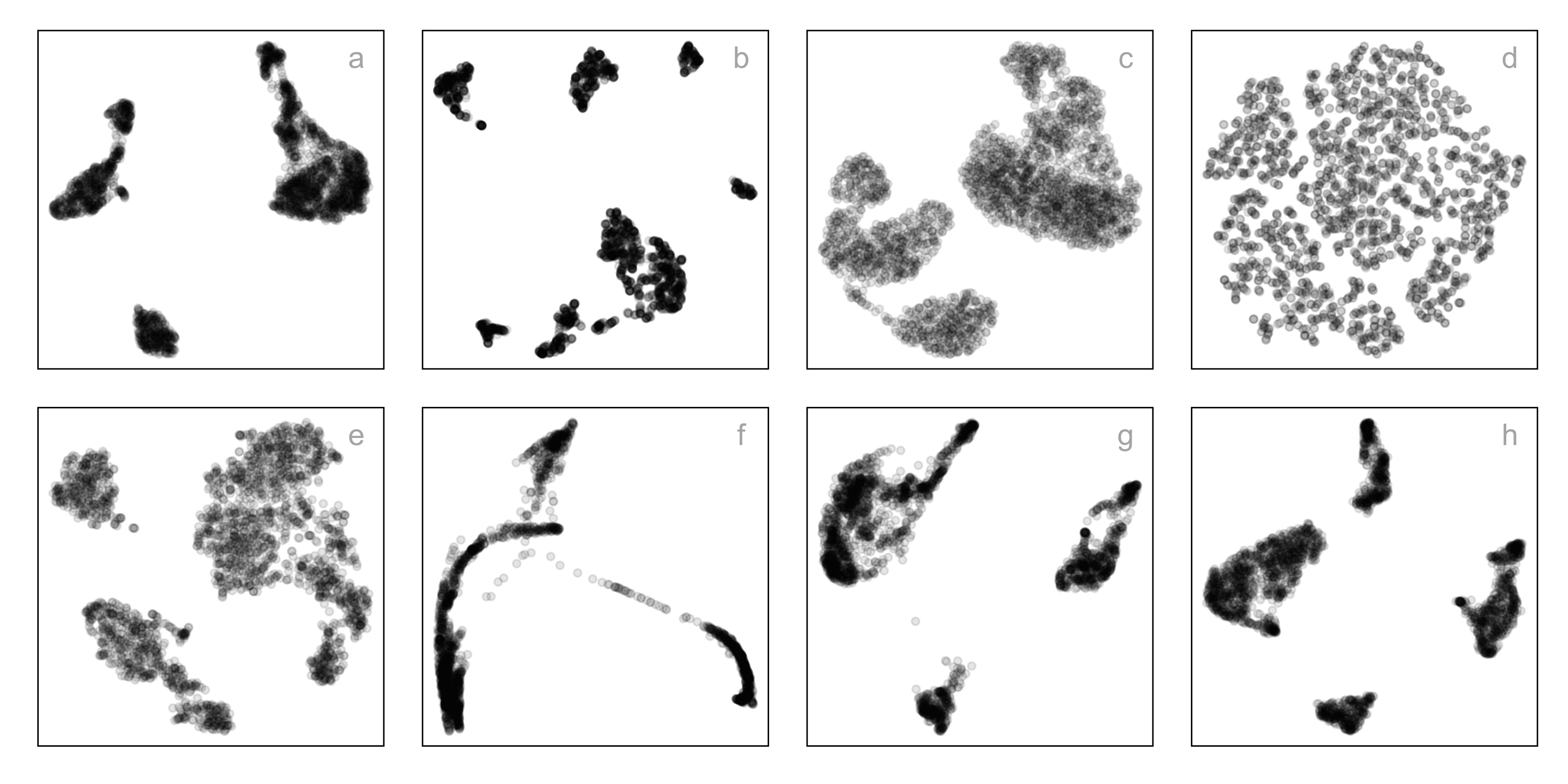
Candidates for NLDR layout
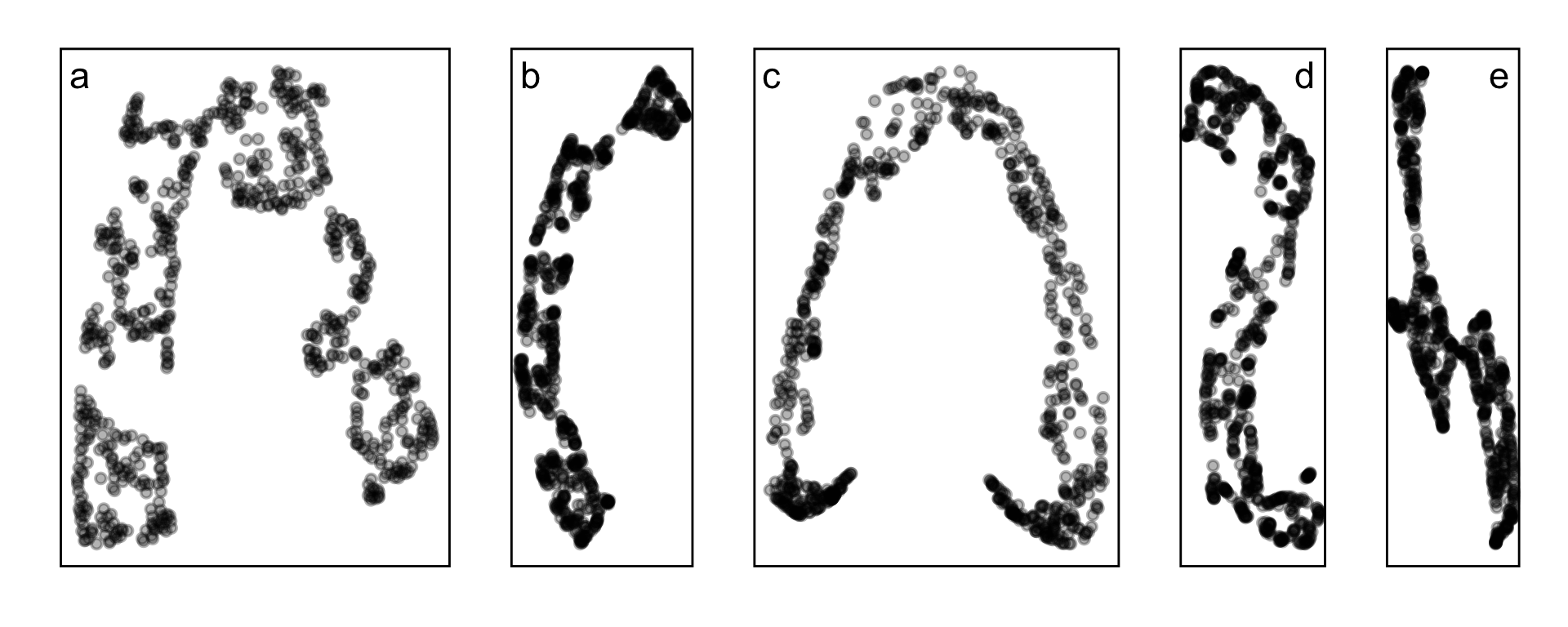
- tSNE, b. UMAP, c. PHATE, d. TriMAP, e. PaCMAP
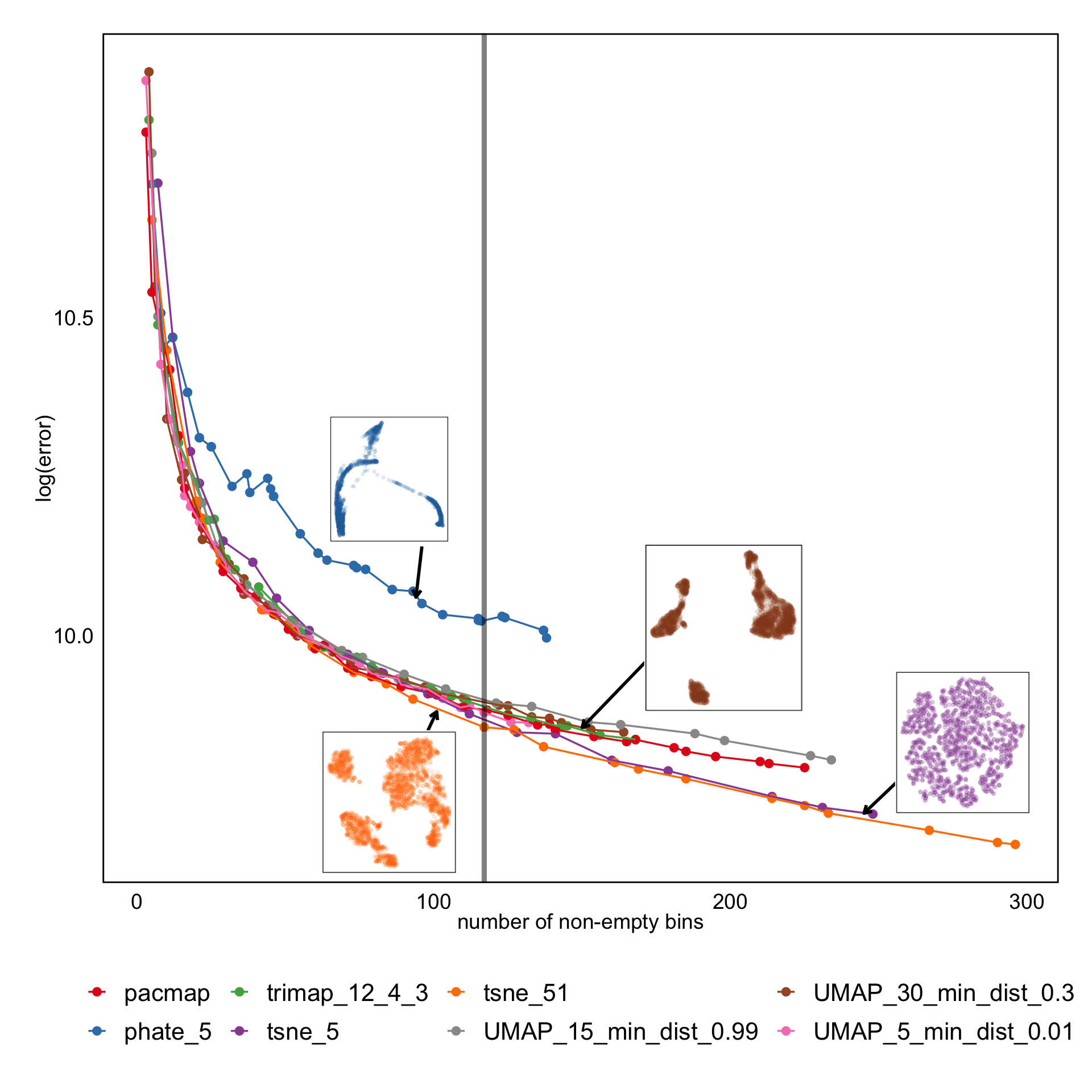
MSE of candidates
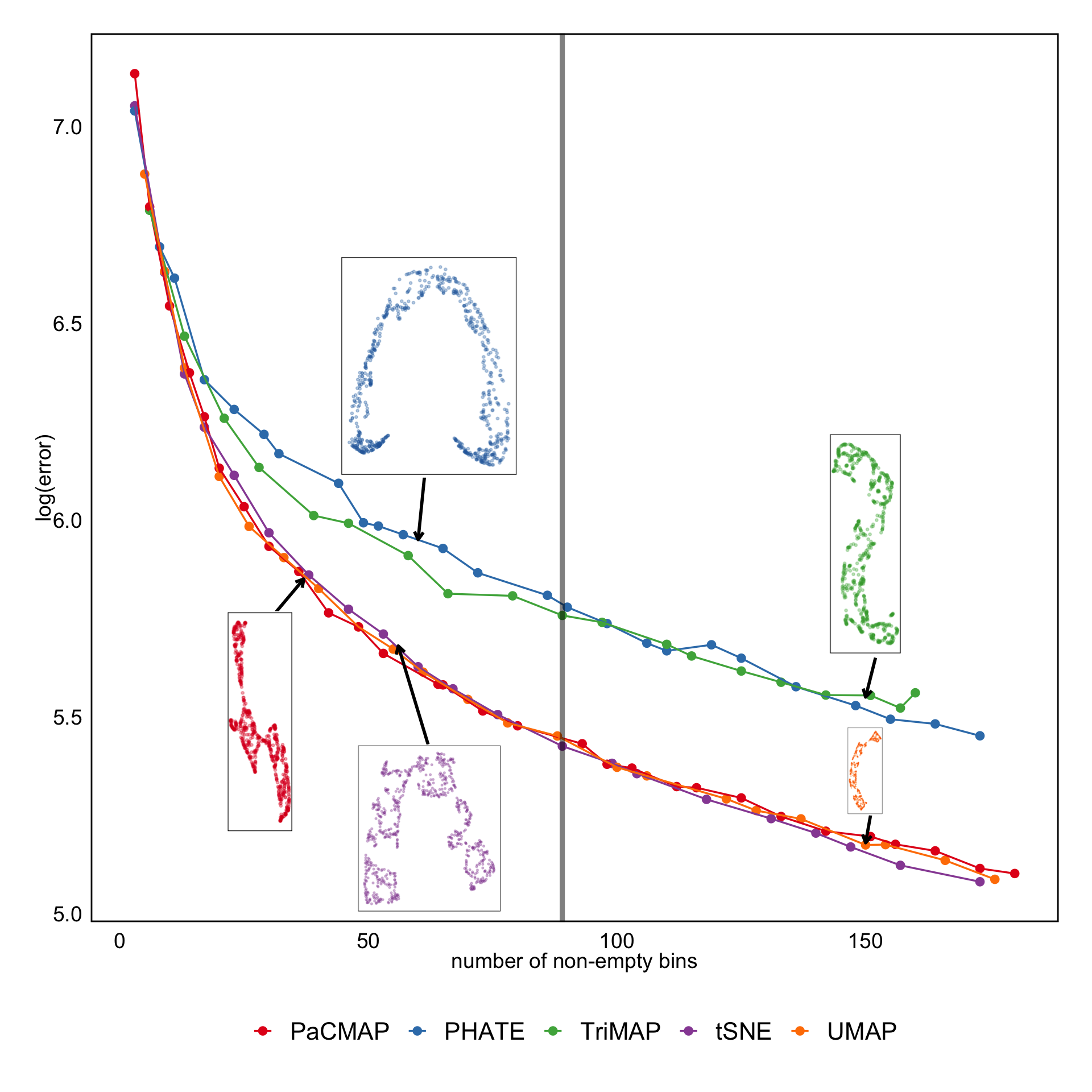
- PHATE, TriMAP not competitive
- Not much difference between any other method based on MSE
- No elbow, just gradual decrease as number of (non-empty) bins increase
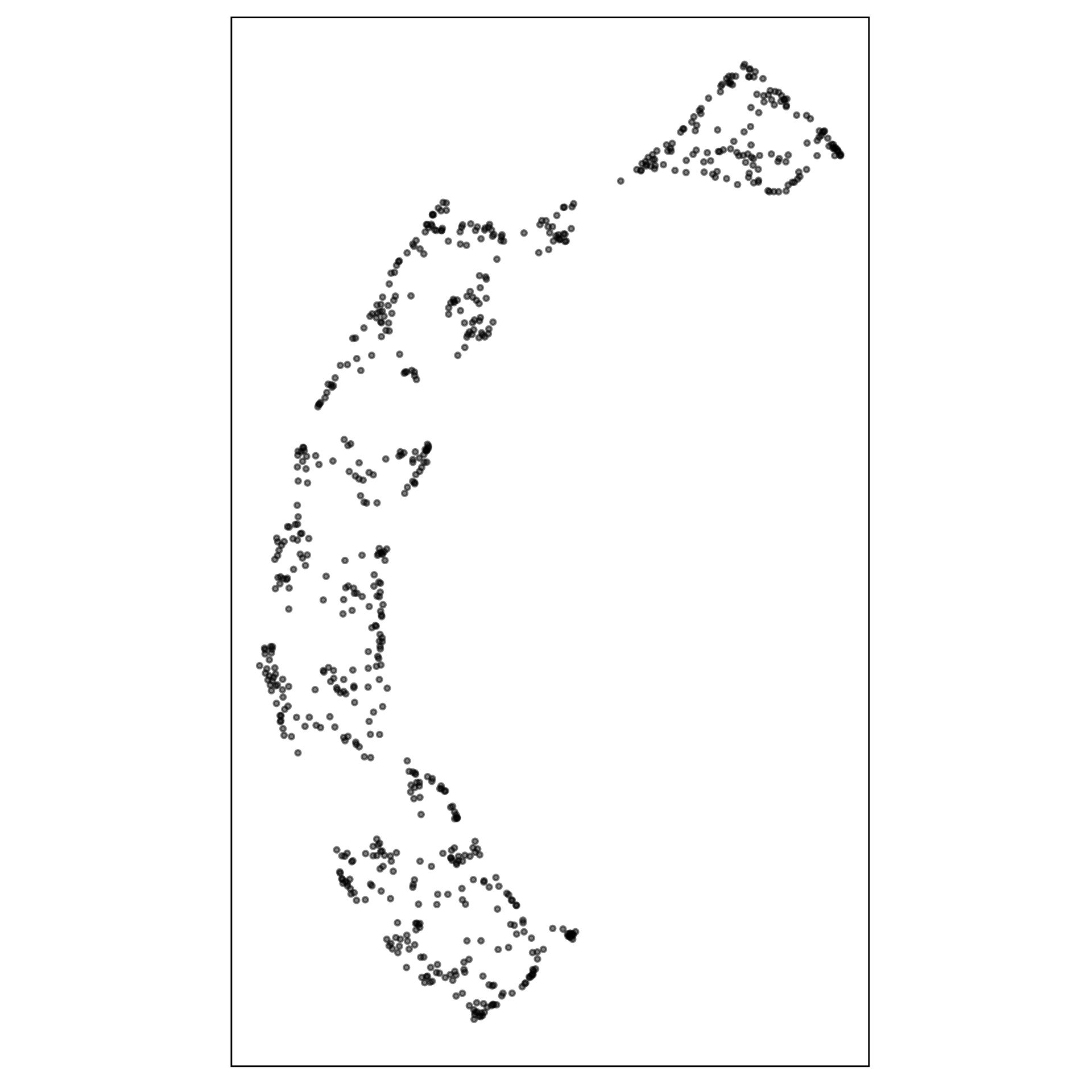
Best fit for S-curve
tSNE with perplexity: 27
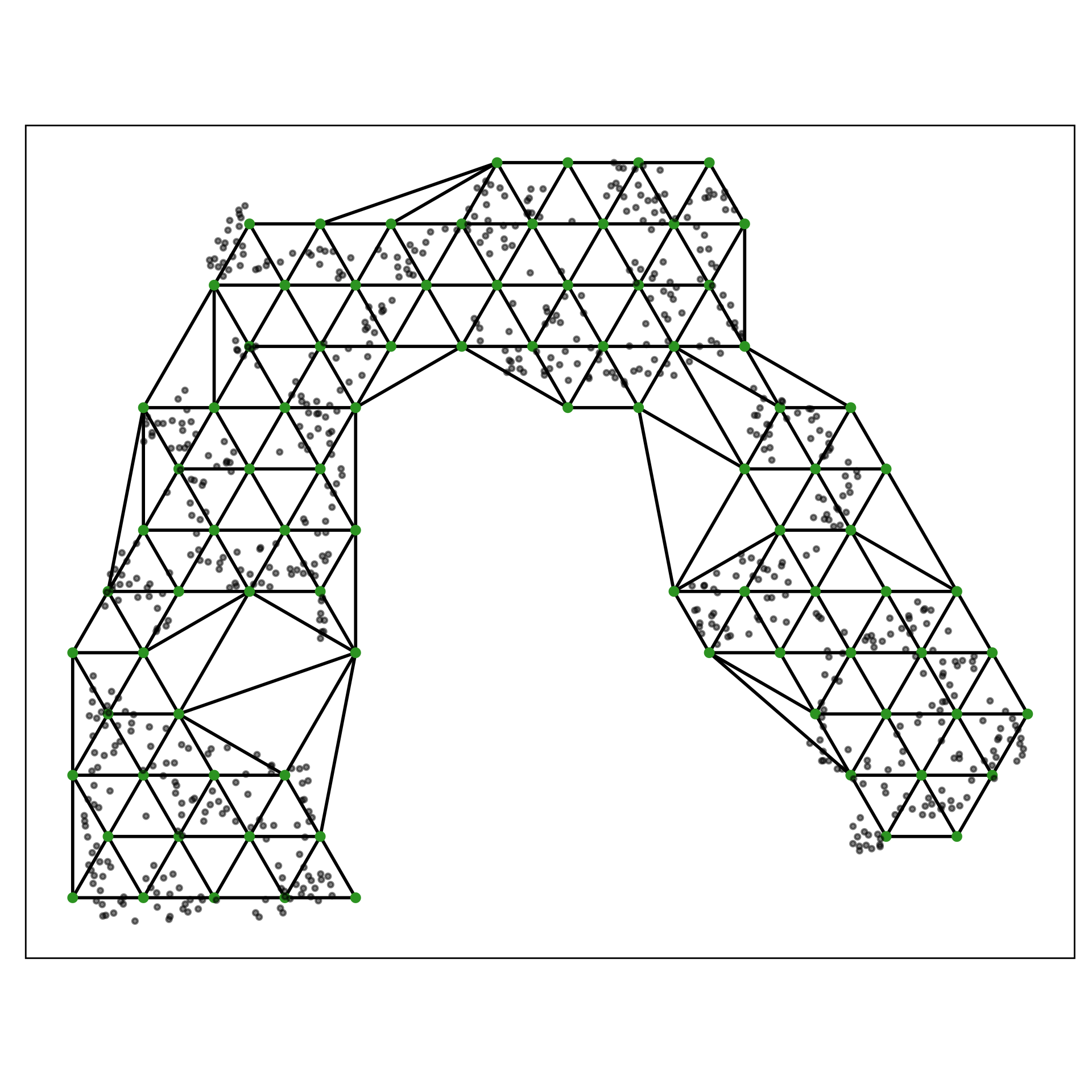
Pretty good! Can you see the twist??
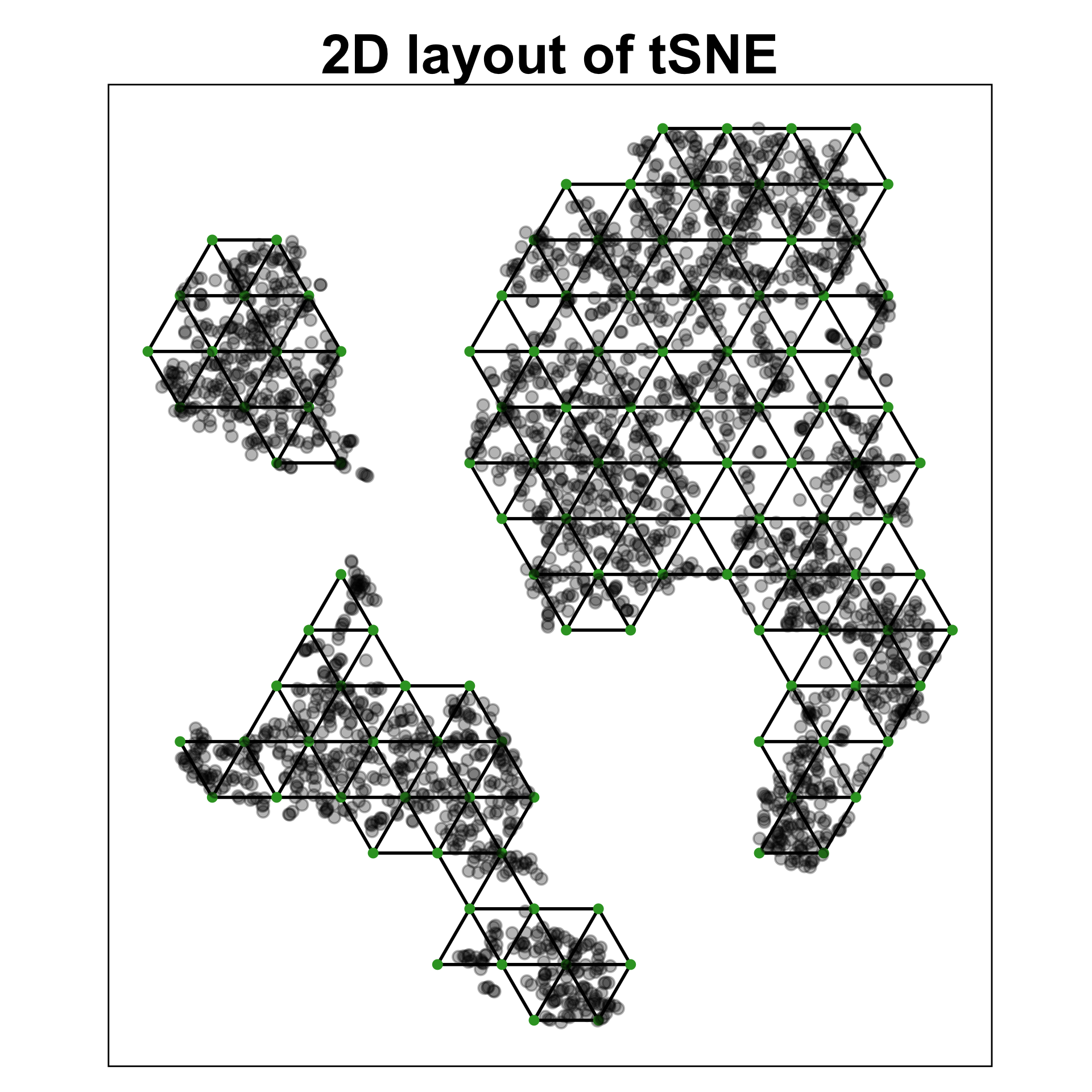
PBMC data set
Best fit for PBMC data set
tSNE with perplexity: 30

Jayani P.G. Lakshika 
Collaborators: Prof. Dianne Cook, Dr. Paul Harrison, Dr. Michael Lydeamore, Dr. Thiyanga S. Talagala